I recently got a copy of Hazel and have been doing a bit of tinkering around with various ways to automate my file management. Because, y’know, I can do it by hand, but why would I when I can make a computer do it for me? That’s the whole point of computers, after all.
I have a great deal of PDFs — something about scanning every paper, handout, receipt, or bit of mail I’ve received in the past six years or so does that. And if you have a commercial-grade scanner, it can be pretty easy to automate that stuff with Hazel, as the scanner will run everything it scans through Optical Character Recognition, and the PDF you’ll get will be nicely searchable.
Unfortunately, the scanner I’ve got, while a pretty good one, is in a different price tier than the ones that’ll do the automatic OCR, so I needed a way of doing that after the fact.
There are some guides to doing that, such as this one, but they tend to require either Acrobat Pro or PDFPen Pro, which both have price tags above the “a couple hours of tinkering and no money” that I was hoping to spend on this project.
Throw a few computer science keywords on what you’re Googling, though, and you’ll find stuff that’s more in that vein. So, compiled here after I used Chase as a guinea pig, a guide to putting together automated OCR for free.
Prerequisites
Before we can automate OCR, we need a few things installed. Open up Terminal, and let’s go.
sudo easy_install pip
(For those of you who didn’t put a few years into classes on computer science, I’ll try to explain as I go along. That first word, sudo, means “super user do”, basically; it’s the Admin Override for terminal commands. Be careful with it, you can make quite a mess tinkering with it. The next bit, easy_install, is part of the version of Python that comes default with macOS. pip is what we’re telling easy_install to install; ironically, pip is the modern version of easy_install.)
The first time you use sudo in a Terminal session, you’ll be prompted for your password; if you’re not an administrator on the mac you’re using, you’ll need an administrator password. That’s a good opportunity to check with the administrator if this is something you should be doing at all.
Once pip is done installing, we’re going to get another installation helper, Homebrew:
sudo /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
Again, this is just installing a piece of software, Homebrew.
Components
Now that we’ve got the infrastructure built, we’re going to install the components that the OCR system uses.
brew install tesseract
brew install ghostscript
brew install poppler
brew install imagemagick
(If any of those fail, you can try to rerun them with sudo added to the front, i.e. sudo brew install tesseract.)
For reference: Tesseract is the actual OCR engine, Ghostscript makes it easier to interact with the PDF format, Poppler is similarly PDF-related, and ImageMagick handles conversion between basically any types of images.
Finally, we’ll use pip to install a specific version of another:
sudo pip install reportlab==3.4.0
ReportLab is yet another PDF-related library, but version 3.5.0 has some compatibility issues with the OCR system.
Installation
Finally, we’ll get the actual thing that ties these all together:
sudo pip install pypdfocr
PyPDFOCR is a lovely open-source project that ties all these components together into a single thing. Once it’s installed, you can use it from the terminal:
pypdfocr {filename}, where you replace {filename} with the non-OCR’d version of the file you want in OCR’d form. It’ll take a bit to run, but once it’s done, you’ll have a file (named {filename}_ocr.pdf) that contains, hopefully, the text of the document you scanned.
Go ahead and test it; if you get an error about the file not being found, see if the file name or directory structure included a space. If it did, tweak the command a bit: instead of pypdfocr {filename} you’ll need to do pypdfocr "{filename}".
You may also get an error that mentions File "/Library/Python/2.7/site-packages/pypdfocr/pypdfocr_pdf.py", line 190… and a bit more after that. If it’s AttributeError: IndirectObject…, then you’ll need to tweak part of the code.
cd /Library/Python/2.7/site-packages/pypdfocr
sudo nano pypdfocr_pdf.py
That’ll open up nano, a very lightweight text editor. Press control+W, type in orig_rotation_angle = int(original_page.get and hit return; this will take you to the line we want to edit. It’ll read orig_rotation_angle = int(original_page.get('/Rotate', 0)) — we want to change it to orig_rotation_angle = int(original_page.get('/Rotate', 0).getObject()) by adding .getObject() before the last close-paren.
Once you’ve done that, press control+X, then hit return again. Try OCRing something again; it should work this time.
Using Hazel
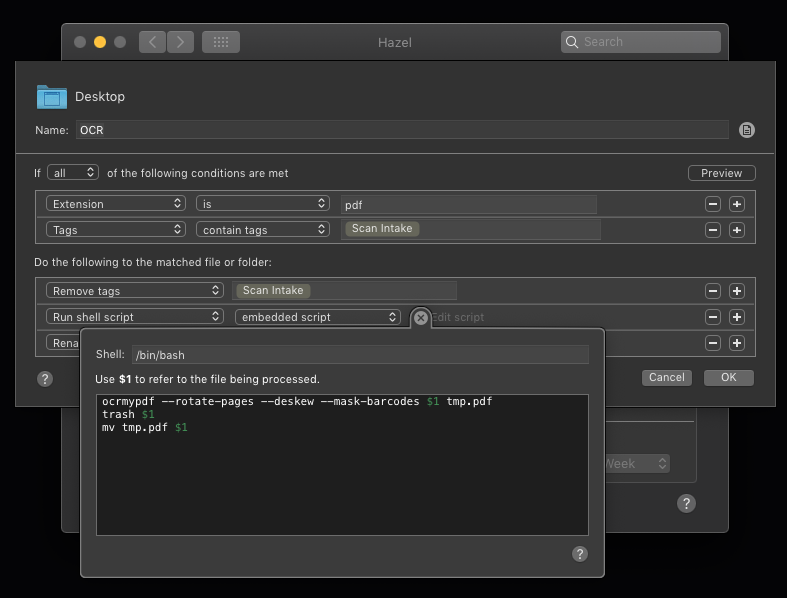
Now all you need to do to have Hazel automatically OCR a PDF is, in the actions, add a “Run shell script” action, use “embedded script”, and in the ‘edit script’ bit, put in pypdfocr "$1".
Keep in mind, this doesn’t replace the PDF in place, it’ll create a copy with _ocr added to the end of the name. If you’d like the original to be deleted once it’s done, rather than having Hazel do it, just add a second line to the embedded script: rm "$1"
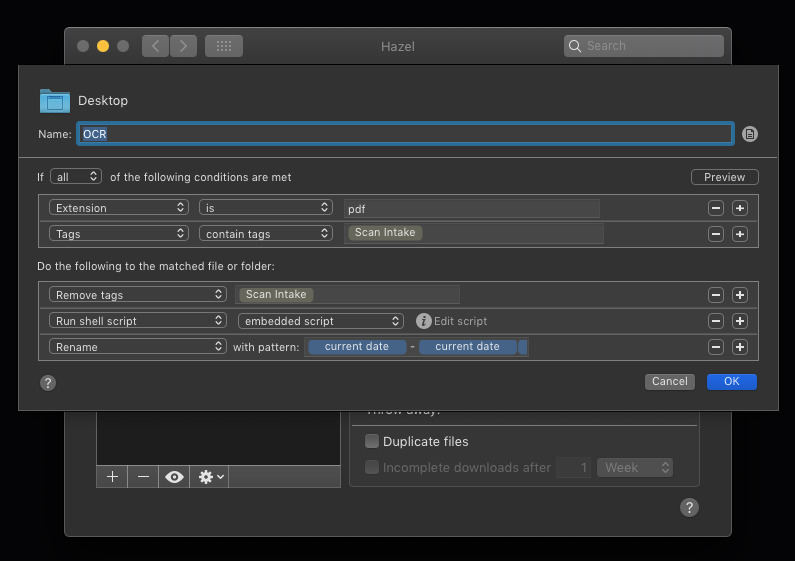
You’ll probably want another rule to move the OCR’d versions somewhere else; while you’re building that, you can also use the ‘rename’ action to remove the _ocr bit, just tell it to replace “_ocr” with “”.
Have fun automating!