I have previously written about how to run OCR (Optical Character Recognition) on a PDF using Hazel and… a complicated pile of Python scripts and other software. Since I wrote that post, several of those pieces of software have been updated, and the core component has been, apparently, entirely abandoned.
Recently, while I was waiting for yet another keyboard replacement on my MacBook, I took another look at the OCR thing and found that there’s a much easier way available: OCRmyPDF.
It’s easy to install, assuming you’ve already got brew: brew install ocrmypdf
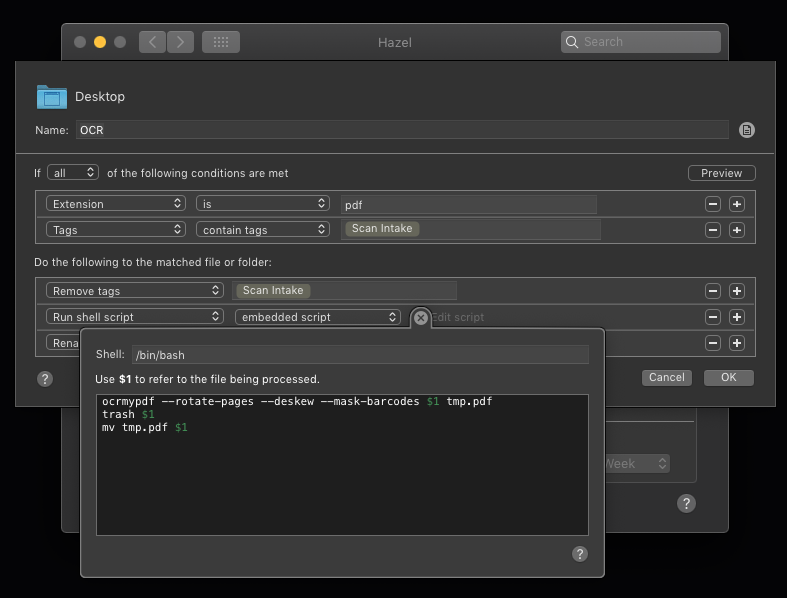
From there, it’s just a single action in Hazel. “Run embedded shell script: ocrmypdf $1”
Admittedly, you can use some of their many settings to get something a bit nicer than just OCR; personally, I’m using --rotate-pages --deskew --mask-barcodes – the first two to help with variations in the input because I sometimes use a bed scanner, and the latter to help Tesseract, which can have issues with barcodes..
I’ve also paired it with a couple additional actions, just to keep everything organized:
I also took the time to stop using Dropbox as the go-between for my scanner and the Mac running Hazel; I’d forgotten that the scanner has a USB port. Plug in a cheap flash drive, and it’s available as a (very slow) file server. Mount the drive, add it as a Login Item so it’ll auto-mount on boot, and you can set Hazel automations to run right there. I’m not OCRing them there, though — like I said, it’s a very slow server, so it tags them ‘for OCR’ and moves them to my desktop.1
- With iCloud Drive handling my desktop, I’ve found it to be a pretty great ‘intake’ folder for all of my Hazel automations. It’s quite nice to be able to save a PDF from my phone, add a tag, and watch it disappear again as it’s auto-sorted, or throw a PDF on my desktop with a tag and see it pop in and out as the OCR runs. ↩
17 replies on “Automatic OCR with Hazel: The Easy Way”
Hi there
I’ve tested your solution but somehow your script does not work. It returns a “shell script exited with a non successful error”. Do you know why? I have macOS Catalina.
Thank you very much for your help!
Best regards
Steve
Hi, thanks for this guide.
I’ve set this rule up but am running into errors the i have no idea how to trouble shoot.
Hazel is just saying ‘error processing shell script on XXXX. When I run the script in terminal it’s giving different errors.
error: the following arguments are required: output_pdf
Do you have any suggestions?
Thanks,
I used the ocrmypdf from the command line and the issue is that you need to specify both an input filename and an output filename:
ocrmypdf input.pdf output.pdf
The error states that it is missing a required argument. When I read through the instructions I was surprised that only a single argument was given.
I have and use Adobe Acrobat Pro for OCR. One file of about 270 pages took 21 minutes on this 2020 MacBook Pro (16G RAM, 2.6 GHz 6-Core Intel Core i7). It was slow because Acrobat “Pro” is only single-threaded.
On ocrmypdf the same source file was completed in just over 9 minutes. It gave warnings about some pages but it kept going. Half of the time was spent running the OCR on the individual page images. Processor meters and the fans showed that the resources were being fully utilized (as it would on HandBrake). The other half was rebuilding the output PDF. That process used a single thread and processor core. Still, there was a significant time savings on this file so I will keep it in my toolbox.
Isn’t it amazing that Adobe, who gets so much from so many users for the subscription to its programs cannot make a multi-threaded program in the past decade when those machines have become ubiquitous. Yet, a free program can outperform it?
What shell script did you use to open ocrmypdf?
I am still stuck getting errors.
The problem seems to be that his code misses two things: the output-file and ” ” around the $1. I got the script to work when looking like this (in the most basic form):
ocrmypdf “$1” “$1”
Thank you so much Grey. I’ve been googling for an OCR option and finally stumbled onto this post.
As James mentioned the script requires input.pdf output.pdf so I just added another `$1` to the script to work in Hazel:
`ocrmypdf $1 $1`
Hey Bradley, would you mind posting your entire script? I get the same execute error as previous commenters experienced when writing `ocrmypdf $1 $1`. Thanks!
I am also running in the execute error. Would someone kindle post their entire shell script that resolves the issue James highlighted?
Thanks so much.
Hi Joe. The current version of the script I have is:
ocrmypdf --rotate-pages --deskew "$1" tmp.pdftrash "$1"
mv tmp.pdf "$1"
I too was having the same problem, and finally got it to work.
I kept mine simple ocrmypdf “$1” “$1”
The trick though was the quotation marks. Regardless if I typed it in or copied pasted from a browser it resulted in “File not found”
The work around was I put Hazel in debug mode:
1) In the menu, select “Hazel→Preferences”
2) Hold down the option key.
3) You should see a new pane called “Debug”. Select it. You can release the option key.
4)Click the “Enable Debug Mode” checkbox.
and ran the rule once. I took the quotations used in the debugger and replaced the quotations in the script. (ocrmypdf “$1” “$1″)
On my screen the ocrmypdf part is white; ” ” are red; and $1 is green if that helps too.
I presume the quotations in terminal might work as well? To see if it’s ocrmypdf or hazel causing the issue, I recommend in terminal typing
“ocrmypdf” a space and drag the file into terminal, once for the input and once more to use the same name as the output (or type a name “OCR.pdf”)
Good Luck.
TL;DR:
Copied and pasted quotes in Hazel debugger to replace the quotations on the script (ocrmypdf “$1” “$1”)
Hello everyone,
I have an odd problem, when I try to run the simple shell script: ocrmypdf “$f” “$f” Hazel returns an error ! Through the debug mode I forund that OCRmyPDF returned error 5: The user running OCRmyPDF does not have sufficient permissions to read the input file and write the output file. Funny thing is when I run OCRmyPDF from terminal it just OCR’s the file. Any ideas ?
Hello again, Found the mistake $f instead of $1, only spend hours going through this… The second pressed post, it dawned upon me.
[…] and even run AppleScripts to extend things even further. There are even people who use Hazel to OCR their invoices and file them away based on the contents of those invoices…it gets pretty advanced if you want it […]
This messaging system seems to publish replies with “curly” or “typographers” quotes. This is not good if one is merely trying to copy paste from the web page into the terminal. Having a forum that allows for source code that is not modified would be helpful here.
The quotes need to be “straight” double quotes around the variables.
The quotes are needed because many file names contain spaces and other special characters that can create all sorts of errors.
I still use ocrmypdf in 2024 when I need a quicker full-resource OCR task. It is generally faster than Adobe Acrobat “Pro”. Considering the cost and the flagship status of the application where many call it the “best in its class,” I am surprised that 20+ years after multi-core Intel Macs were introduced, we still pay for a single-threaded application that uses only 1 of 6 cores on this MacBook Pro from late 2020.
My first multi-core Mac was an iMac Core 2 Duo which I see was introduced in 2006 — some 18 years ago. I’m sure other users had multi-core Macs before that.
Adobe continues to collect subscription fees and yet they don’t make an improved product. Workflow for many common tasks is just bad and it is slower than it should be.
Once OCR’d, can you automagically extract the date of the document (eg invoice) in order to automatically name the PDF file with it?
Almost certainly possible, but I honestly haven’t bothered – in part, because I tend to do the “scan and recycle” thing immediately, so the file’s date modified is an easier source, and in part because I have such an eclectic mix of things going into this system that there’s nothing much consistent to try to run a regular expression against.
You can use pdftotext to extract a date from a document, though it gets a bit more complicated when there are multiple dates in the document.
Example here: https://akrabat.com/renaming-pdf-files-based-on-their-content/