You may have seen my monthly playlist posts on here; I put those together with a Shortcut that grabs the playlist, runs through all the songs, and makes a spirited attempt to fill in all the links off the iTunes Store Search API without hitting their mysterious rate limits.
It’s not the be-all end-all, though — I’ve been wanting more and more lately to start making more and smaller playlists, things to match different moods. Y’know, the way normal people do playlists.
But, of course, I’m me, and I want to have the history of my music tastes, because, hey, sometimes you feel like reminiscing.
So, what to do? Well, I’ve done some work with the iTunes Library XML file, and while it’s sorta true that just wrapping that in, like, Git or something for version control could work, there are three problems with that:
1. iTunes is a weird, weird piece of software, and I don’t want to mess with its files too much.
2. The result is not at all human-readable.
3. It isn’t an excuse to learn something new.
So, what else can I do? Well, I’ve done a very light bit of tinkering with AppleScript, so I know it can interact with iTunes pretty well; there’s gotta be a way to do it there, right?
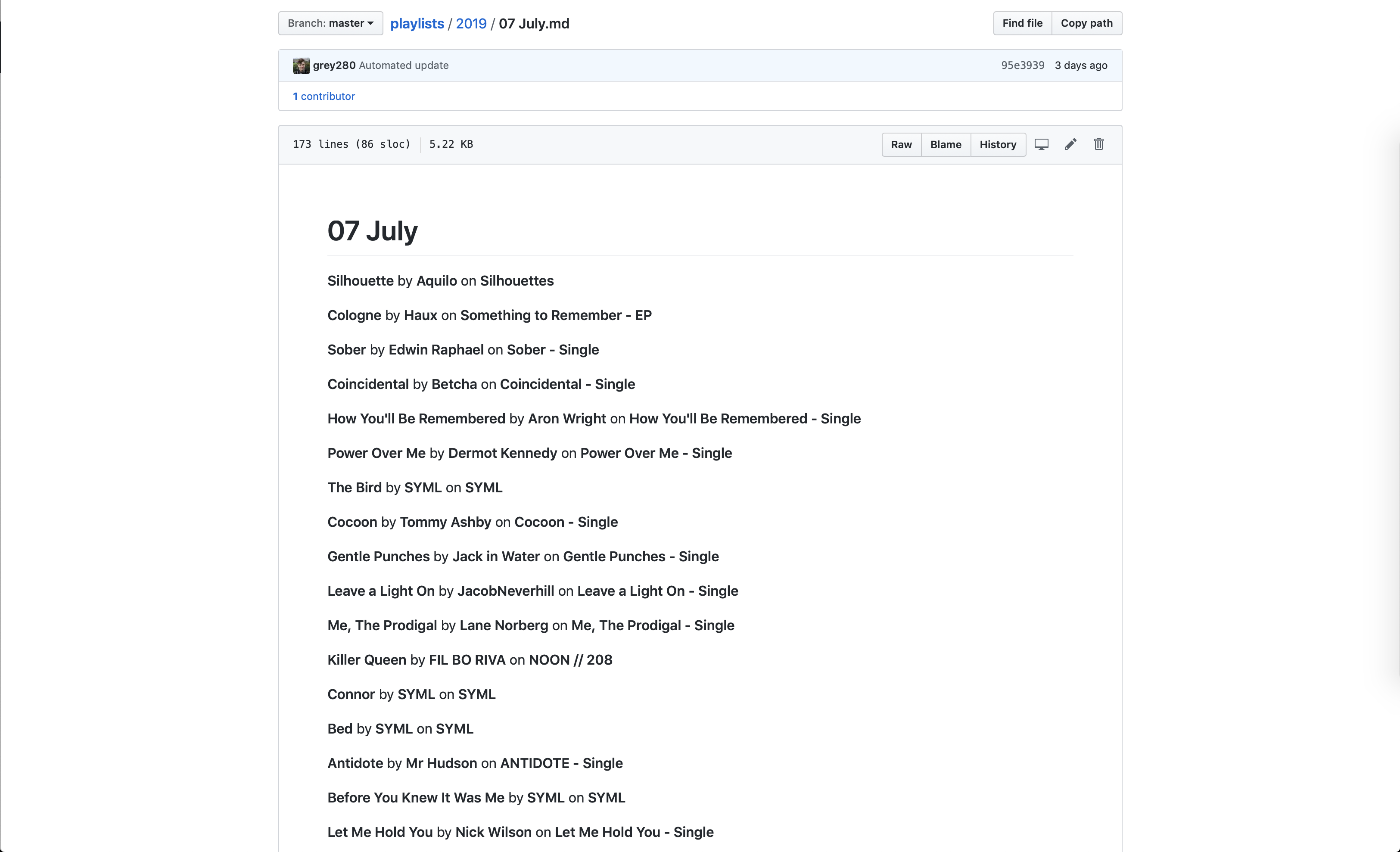
There is! I’ll share the script in a moment, but the functionality I wanted was “clear out the folder I give you, replicate my playlist hierarchy as directories, and spit out each playlist as a markdown file listing the title, artist, and album for each track, then commit the changes to a git repository.”
It took a while to get working — I’ve learned that AppleScript’s repeat with in loop is hilariously slow, unless you change it to repeat with in (get). I’ve also found out that the way it works with paths is super annoying, and that while it can write to a file, it can’t conceptualize creating a directory. There’s some great workarounds for that.
Now, here’s the script: I’ve left a couple {replace me} type things where you should fill in variables – namely, the path to your home directory (or wherever else you want it), and your own username, to fix some permission issues that can crop up.
https://gist.github.com/grey280/9b95fdc8c16ec544a214f159bd008bbc
But wait, there’s a caveat: it’ll fail if the folder you gave it isn’t a git repository. Considering that I wanted this as a ‘set it and forget it’ sort of thing, I figured it wouldn’t be worth the effort to write a bunch of conditional code to do the setup. Do it yourself: git init && touch temp.txt && add temp.txt && git commit -m "Initial commit" takes care of all you need.
Oh, and if you want it to be pushing the changes somewhere, because you’re paranoid and want everything in someone’s cloud, at least, add the remote and set it as the default upstream: git remote add origin {remote URL} && git push --set-upstream origin master
Set It and Forget It
So that’s pretty neat, but it isn’t really “set it and forget it,” now, is it? You’ve gotta open up Script Editor, pull up the script, and run it every time you want it to back up your playlists. Possibly workable for some people, but I don’t have a home server for nothing. Let’s make this truly automated.
From my prior experience with AppleScript, I know that you can set it off through a shell script by way of /usr/bin/osascript, so my first thought was to add a cron job. After a bit of research, though, I found out that Apple would prefer we use launchd instead, so I set about figuring out how to do that.
Now, if this wasn’t all an excuse to learn how to do something, I’d probably have just bought one of the GUI clients for launchd; Lingon looks pretty nice, and seems to work well.
The process for writing your own launchd process is actually pretty simple: create a .plist file containing some XML, add it to the launchd queue with launchctl, and you’re off to the races!
(Hint: if you want an easier way to see if your script runs than waiting and checking git log, you can add a line to the start of the AppleScript: display notification "Running playlist export".)
So, creating the XML: you want it to live in ~/Library/LaunchAgents/, and the convention is the usual reverse-TLD. (You can also use local.{your username}.{your script name}, but I’m so used to using net.twoeighty. in bundle identifiers that I just went with that.)
The important parts are the ProgramArguments array and the StartInterval integer. For ProgramArguments, give it the path to osascript, and as your second argument, the full path to the .scpt of the AppleScript.
Then, set the StartInterval to the number of seconds between runs; I’m using 3600, because hourly change tracking seems frequent enough for my purposes.
The result:
https://gist.github.com/grey280/f643a159a426ae25eb57139afd4f3cd5
(You can skip the StandardErrorPath and StandardOutPath – they help a little with debugging, more so if you’re running a full shell script and not a wrapper on an AppleScript.)
Finally, add it to the queue:
launctl load ~/Library/LaunchAgents/net.twoeighty.backupPlaylists.plist
And there you go – every hour, your iTunes playlists will get backed up to your Git repo, and you’ll have a nice history of your music tastes over time.