About 2/3 of the way through this book, I wound up texting a friend, “I didn’t want t get invested in this book, because it’s creepy, but here I am, queueing up the nightmares.”
And, really, that’s a great summary of the book. It’s definitely creepy, but it’s also enrapturing. Think of… a swamp. It’s a place of decay, and death – but also, full of so much life. Beautiful, and terrible; ancient, but always changing. That’s how the story feels, all the way through.
In short, it’s excellent. Not too long a read, so not too long a review, but I quite liked it. Check it out.
I enjoyed “Carry On” so much that I immediately picked up the sequel and read through it. “Wayward Son” is also a fun read, but not nearly as strong as “Carry On” was; “Carry On” is a conclusion and a beginning, while “Wayward Son” is… the middle book.1 It feels like it’s trying to progress the arc of the story, while still leaving enough un-finished for there to be a properly conclusive sequel — to the degree that the “ending on a cliffhanger” doesn’t actually add much more “well, guess I need to read the next one to see how this ends” than the book already had.
Still, there’s a lot of fun worldbuilding going on — an actual proper treatment of what the United States is like in this magical world, unlike Rowling’s utter disregard for… our entire culture, really.2 It honestly leaves me wanting to see other countries in this world, as well. Anglocentrism fits something that started as a Harry Potter parody, but now that we’ve established that Magical Britain is Britain and Magical America is “America, but more libertarian”, I’d love to see, like, Magical Brazil. Magical China. Fill out the world a bit more — what sort of international laws are there governing magic? How does the rest of the world deal with the fact that the Magical United States has no government, and the only thing keeping magic from going viral is that all the magic-users are secretive by nature? Lord knows that won’t last.
I’ll wrap up my rambling here, though. It’s an alright book; I think my main issue with it is timing. If I’d been able to go through all three in the series in a row, I suspect I would’ve enjoyed it a bit more — there’s a lot of set-up for the next book, but now, instead of getting to carry right on to the pay-off, I’m just stuck waiting. So, y’know, maybe wait until next year, but then read it.
Literally so: there’s a third book in the series, scheduled to be released next year, which is explicitly billed as “the third and final book in the Simon Snow series.” ↩
The Fantastic Beasts film actually did an alright job of portraying my country, it feels like, but every aspect of the magical school she tried to describe as our equivalent to Hogwarts is extremely “I don’t get America.” We don’t do school houses, and you really think we’d have a single school? (I must admit, I really love watching Europeans be utterly unable to grasp just how big the US is.) ↩
I keep going back and forth on whether or not I think this book is a parody of the Harry Potter series. On the one hand, it really obviously is – magic school in Britain, Chosen One, mysterious villain, rival from Old Money.1 But it’s doing so much more than just poking fun at these things that have become tropes; it has its own story to tell, and a system of magic that honestly makes more sense than anything Rowling ever accomplished.2
But a good part of my enjoyment of the book is also in the contrast with Harry Potter. What if Harry and Draco had been roommates? (And yes, it’s magic, so we do get to say “they can’t just strangle each other, the school has magically-enforced rules about that.”) What was Draco thinking when Harry was doing the “I have to keep an eye on him at all times” thing in their whichever-th year?3
The opening couple chapters are a delight to read. It’s the start of the school year, which makes for a very clear narrative beginning point… except it’s the start of Simon’s final school year, and he’s been a Protagonist all along, so we’re coming in very much in medias res. The amount of “as you know, Bob” is kept very low, which makes it a fun puzzle of “what all Insane Bullshit has he survived so far?”, and I’ve always enjoyed a game of “what’s the setting.”
Suffice it to say, I heartily recommend this – I’ve been trying to reduce the number of books in my to-read pile, but the moment I finished the book I immediately ordered the sequel, so here we are. If you at all like Harry Potter, and want something without the… tainted association of Rowling, please do read this delightful book.
For reference, the titular character, and all the adventures that he went through prior to “Carry On,” made their original appearance in a novel centered around someone’s enjoyment of We Can’t Call It Harry Potter Because Rowling Has Lawyers For That, so it’s no surprise that there’s a lot of clear similarities. ↩
There’s rules! Actual rules, explicitly stated, about how spells are created! And they aren’t “yeah there’s an insane AI somewhere running things, it thinks making us make those noises are funny and rewards us with making stuff happen.” It’s all I ever wanted. ↩
For reference, here’s how I summarized that to my friend, while I was reading: “Harry is over there like ‘he’s gotta be up to something!’ Draco, meanwhile, is like ‘please, I am a fifteen year old boy, I need five minutes of Alone Time to deal with a… personal matter.’” ↩
I remain a complete sucker for good worldbuilding, and this is a very fun world that Hale has built. Gilded Age America, but with magic around, things went a bit differently – not least of which being that a magical war cracked the continent in half, leaving California an ocean away. In the meantime, magic has been severely regulated, and oh, don’t forget the automatons everywhere. It’s an interesting place.
And that’s without touching on the protagonists, who have an astonishing amount of backstory for such a short book.
It’s a short read – took me less than an hour, once I’d gotten invested – and I heartily recommend it. Give it a read.
Now that Big Sur is out and I can do a full-SwiftUI app on macOS, I’m back to being very tempted to make a little utility app to simplify the process of writing up these playlists.
At some point I might have to look up a translation of the lyrics here. I’m a little curious. ↩
May or may not occasionally just crank the volume and sing along to this at the top of my voice. ↩
Far and away my favorite new song this month. I have no idea why, but this one hits me right in the heartstrings. ↩
This whole album has big “closeted in the Midwest” energy. Not sure if that’s a good thing or a bad thing. ↩
Listen, sometimes you just need some rap that you absolutely can’t understand, okay? ↩
Some of the same sounds as “Bury A Friend,” which unfortunately is less effective here, because, y’know, Billie Eilish is already Billie Eilish, and not pioneering this whole new sound this time around. ↩
A lot of “musical theater” vibes to this one – it’s the key changes. ↩
Somehow I stumbled across a Tiktok where Oh teased this song, and I liked it enough from that that I just threw a reminder in Things, “in two weeks remind me to see if this song is out.” It was! ↩
There’s a sound in here, I think somewhere around 1:20, that reminded me so intensely of Majik that I wound up adding Friends to the list. Man, I miss Majik. ↩
I haven’t actually read very much Kipling, so reading a collection of stories inspired by — or, possibly, “in reaction to” — his work has me feeling like I’m almost certainly missing some context.
In reading, though, I didn’t find these stories at all lacking. They’re well able to stand on their own, and I’ve picked up enough from cultural osmosis to at least feel the shape of some of the references.
It’s also interesting to see the various storytelling methods and traditions being referenced here. Sometimes it’s a story you’re reading, and other times, you’re being told a story, spoken to directly. In a few of the stories in the book, it switches back and forth between these two approaches, telling two stories at once, one nesting inside the other. Reminiscent of Cloud Atlas, in a way.
The thing that most surprised me, as I read this, was how wrong my expectations were. “Based on Kipling’s Just So Stories” had me expecting everything to be in following the Platonic Ideal of a children’s book, very little conflict, everything easily resolved. Instead, in many of these stories, I found myself enraged and saddened at the injustice of it all. Many of them don’t have a happy ending; many of them don’t have much by way of happiness at all. In that, they feel more real than what I was expecting would’ve, although I so much hate to say it.
But my hatred for saying that is a response to media where that sadness feels like it’s there for sadness’ sake. Looking at you, DC film universe — the whole “grim and gritty” thing is just depressing, and the world is depressing enough already.
But in Not So Stories, for the most part, the unhappiness isn’t there just to be unhappy. It’s there to highlight that things aren’t fair, that the world doesn’t always go right — and to make you mad at that. To make you want to change it.
It is, in retrospect, an enjoyable reading experience, though at times I didn’t feel that way. Go read the book, and get mad at injustice.
I realized, somewhere around a third of the way into this book, that I don’t actually like anyone in it. The protagonist is an astonishingly boring man, for someone living through this upsetting a series of events, and the other main character is a rather good example of what’s wrong with acting like a proper Victorian.
All that said, I did enjoy the book. It was the kind of mystery that I enjoy, less about figuring out who did the thing than it as about what, precisely, they did. That mystery is what carried me through – I had theories, thoughts about what might have been going on with that second main character, and I had a great deal of fun trying to figure out which of them were right, which were wrong, and why. (And, it turns out, I was wrong on all counts – the end was stranger than I expected, and all the more creepy as a result.)
All told, I quite enjoyed this book, and I can recommend it to anyone who likes a creepy mystery. (Bonus points if you like Victorian literature — you’ll probably catch more of the references than I did.) If that’s you, give it a read.
Every time I go to file a bug report Feedback with Apple, I have to remember how to gather a sysdiagnose; on macOS, the whole diagnostic process is automatic in the Feedback app, and if you have Feedback installed on iOS, it is there too. I, however, make things difficult on myself, and use Feedback on macOS to submit my iOS bugs.
A sysdiagnose, for those wondering, is a big bundle of diagnostic information that Apple (or the developer of an iOS app) can use to figure out what exactly went wrong when something didn’t work right on your device.
Since Apple’s documentation on how to gather a sysdiagnose leaves out a few key steps (FB8739343, if anyone at Apple is paying attention to this), I figured I’d write up the process for myself for future reference.
Without further ado, here’s how to gather a sysdiagnose on an iPhone X-class device. (Read: ‘no home button’)
Press the volume up, volume down, and lock buttons all at once, and hold them for ~1 second. You’ll feel a little haptic buzz; your phone might also take a screenshot.
Wait. Apple recommends about 10 minutes for iOS to gather everything.
Open Settings and go to Privacy > Analytics & Improvements > Analytics Data
Scroll through the list until you see a file whose name starts with “sysdiagnose_” and then the current date. (Protip: this list is super long, so once you’ve started scrolling, you can tap and drag on the little scroll blob on the right side of the screen to zoom through hit much faster.)
Tap on the file, hit share, and AirDrop it to your Mac. (Or save it to iCloud, but I heartily do not recommend trying to email or send it via iMessage – it’s probably like a quarter of a gigabyte.)
Hopefully this helps you, and as someone who has to try to figure out why software isn’t working right, thank you for taking the time to get all the diagnostic information – it’s very helpful.
If you’re a fan of Warehouse 13, you’ll enjoy this book, I suspect. While it’s not as visibly rooted in actual historical fact as Warehouse 13 always was,1 it’s got that same “Indiana Jones, but about saving the world instead of just finding cool stuff for the museum” vibe.
That’s, really, most of the tl;dr of the book, although I’ve left out the magic. It’s a somewhat loosely-defined magic system, which normally I’d be annoyed by, being the “I want to understand the laws of magic” person that I am, but in this case it fits the cinematic feel of the series. The only really solid rule is that magic doesn’t come from people, but is a natural thing — ley lines! — that they channel through a focus of some sort. There’s also a lot of dangerous ancient artifacts around, which is where we get the Warehouse 13 aspect.
Zoe makes for a reasonable protagonist in Ancient Magic and Cursed Magic, but I think Hayley, the protagonist of Hidden Magic, is the one who really makes this collection. Zoe is the seasoned veteran, someone who was raised with magic and made a career out… well, being a badass. Hayley, meanwhile, is a junior museum curator, and spends the first quarter of her story in the perfectly reasonable belief that magic isn’t real. Discovering it with her is a lot more fun, and that “what is happening” mindset makes her a lot more relatable to the reader. Frankly, I’d argue that Hidden Magic should’ve been the first book in the collection, but Ancient Magic dovetails into it so well with the little crossover that it’s hard to be mad.
End result, I quite liked this little collection. It was a pretty quick read, and a fun one; give it a go.2
Well, right up until it wasn’t, but you’ve gotta let the show have its core concept, after all. ↩
Normally, this would be a Bookshop link, but I’m unable to find the collection — or any of the component novellas — on Bookshop, so here’s an Amazon link instead. Strangely, despite being published under the same title, the thing I’m linking to is a 6-novella set, while the one I read only contains the first 3. I, frankly, have no idea where I got this ebook. ↩
I like this song because it’s kinda about the importance of communication in relationships! Positive influence! Of course, Escape is also on this album, and that’s a song about a woman who needs to get a restraining order and a gun, so… ↩
Now that the Bon Iver song off this album is thoroughly overplayed in my head, I’m listening to other parts of it. ↩
Can you tell that I’ve become a big fan of Yoste? ↩
I sent this song to a friend with this note: “and I love Woodkid because that isn’t even his horniest song, but Woodkid Horny Music is EXTREMELY different from regular horny music” ↩
This song had no right to hit as hard as it did, I, as a former Choir Kid, feel called out. As a side note, this was real fun to search for in Apple’s link building tool, which intermittently doesn’t know about unicode. ↩
One day I’m gonna have a sufficient dataset, thanks to all these playlists, that I can do some fun analysis. I’m betting The Fray is gonna be on an annual cycle. ↩
So far, my favorite off the new album, but I’ve also only listened to about half of the album so far. ↩
This album is kinda all over the place, but I love it ↩
People say not to judge a book by its cover, but looking at the cover of this book having just read it, I think it does a remarkably good job of explaining the book. The title really covers a lot of it, and the porthole hints at the little bit of steampunk that drifted in around the edges of the ‘werewolf’ bit.
In short, the book is utterly ridiculous. It’s not quite as “empty fluff”-y as you might think, and has some interesting things going on with some of the backstory, but it’s still entirely ridiculous.
But you know what? It’s 2020. The world sucks. Let people enjoy things! Read a ridiculous werewolf-regency-romance novel!
You can judge this book by its cover, but think about what context you’re using to judge it. Does “ridiculous and fluffy” mean bad? Or is it that it’s feminine-coded, and our sociocultural background has spent our entire lives teaching us that we should frown upon that sort of thing?
I was going to start with “it’s been a while since the last anthology I read and reviewed,” but, as it turns out, it hasn’t. I wonder if it’s the variety of stories that makes an anthology feel further away in my memory? No single story has as long to get lodged in my memory, or something. Hmm.
Still, I do like the anthologies – they’re fun in the same way that a 22-minute-long TV show is, a great way to fill a bit of time without getting yourself too invested in something.
Knaves is, admittedly, less fun than some of the other ones, because the focus is on villains. So, by the nature of their stories, it’s a bit of a gloomy topic.
Which isn’t to say the stories aren’t interesting, because they absolutely are. “All Mine” is heartbreaking, as is “Hunger in the Bones”; “The Bloodletter’s Prayer” is a fascinating piece of dark fantasy; “Cat Secret Weapon #1” is a delightful spin on the Bond archetype; “The Hand of Virtue” is sweet and a touch melancholy; and “Old Sol Rises Up” is… well, honestly, mostly confusing. But I suspect that was the intent, so I won’t fault it.
And, of course, there’s an introduction – every anthology has to have one. What caught my eye and, frankly, got me to actually read the introduction was who wrote it – Howard Tayler, the man behind Schlock Mercenary, another delightful piece of media that I’m happy to recommend. Read the intro – it’s weird, and silly, and fun.
Craig Laurance Gidney This book is… melancholy. I read it in bits and pieces over the course of a couple of months, which it’s well suited for, as a collection of short stories. Some of them were creepy, and some were sad. One or two were happy, and hopeful. But overall, the feeling I have is melancholy. Part of that is the way the last story ends, which is certainly coloring my opinion, as I set the book down and immediately started writing this, but I think the whole thing feels that way, as well. Melancholy certainly isn’t the best of moods to be in, but sometimes it’s what you need. And, considering that I’m posting this as we’re making our way into autumn, it’s entirely appropriate. Get yourself a seat looking over trees preparing to shed their leaves, a mug of tea, and read this book.
Part of the MHCID’s program requirements is that we give a presentation, detailing what we did during the internship. This year, gathering everyone together for a TEDx-style event… wasn’t in the cards. Instead, each group made a video presentation, filling approximately the same niche.
It’s been a while since I had a chance to do any video editing, and I had fun putting this together. As mentioned in my previous posts about this project, it was a group effort – we each recorded part of the audio, and split up the work of finding video clips, icons, and images to go with what we were saying.
It was fun to put together, and I’m pretty happy with the end result. Check it out:
I’ve just released Fluidics 2.1 on the App Store, only five months after the last update, so I’m speeding up a bit on my release cycle, apparently. If you’d like to see the whole “what’s new” list, check out the release post over on the Fluidics site; this post is more of a “making of” kind of thing.
Unlike the last update, this wasn’t a ground-up rewrite. I briefly considered tearing out the App/SceneDelegate stuff and rewriting it to use the new SwiftUI-style App setup, but because there were some visual bugs with the release of iOS 14, I wanted to get the update out sooner rather than later.
This version requires iOS 14 – the previous version has no issues on iOS 13, and just about everything new in 2.1 requires iOS 14, so I went ahead and bumped the minimum version.
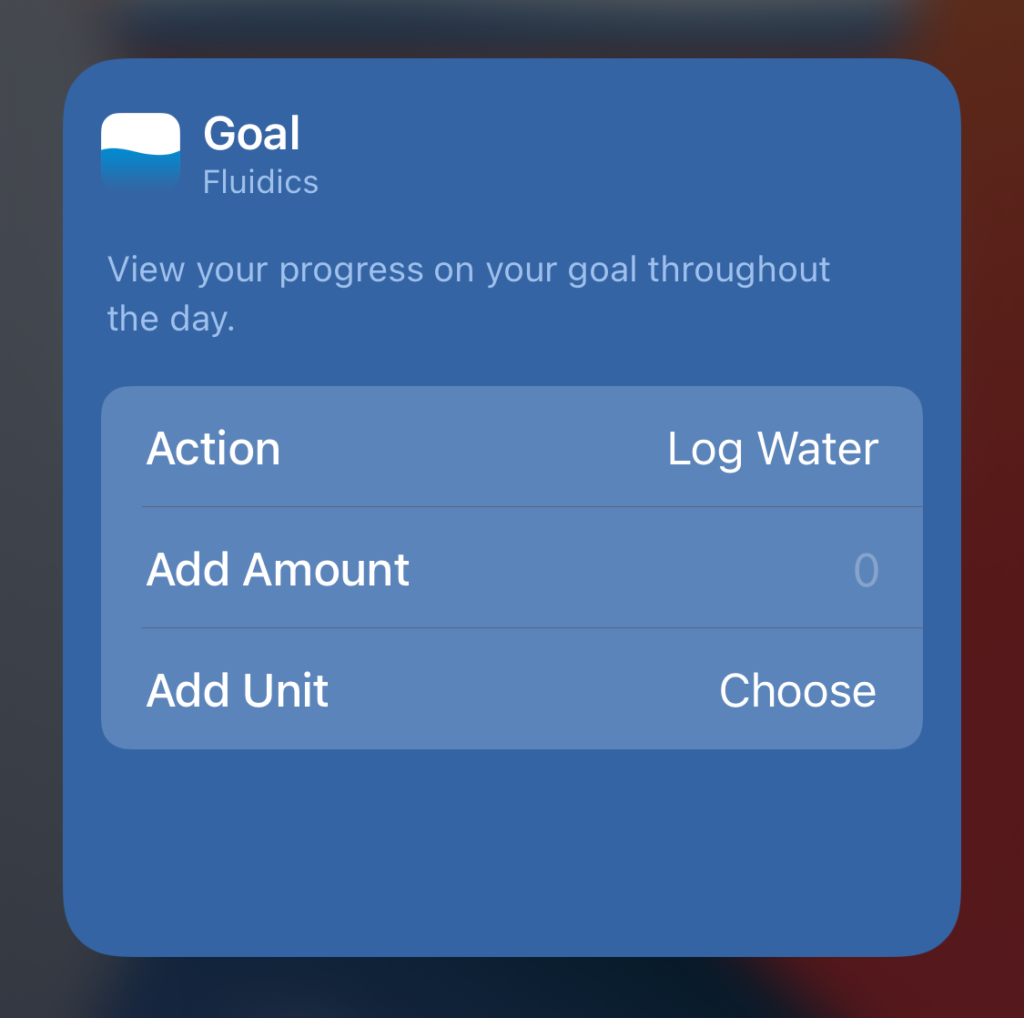
The main addition in Fluidics 2.1 is the new widgets, available with three variants.
From the top:
The ‘add’ widget, which displays the four Quick Adds, and allows one-tap logging from the home screen.
The ‘status’ widget, in wide form – my personal favorite – which displays the goal, not only in the fill state of the widget background, but also in text form, as well as the four quick adds.
The ‘status’ widget, in small form, displaying just the goal in text form.
All of the widgets allow launching the app, and use deep links to interact with it in specific ways.
The linking format is technically open, so I can drop a link into this post that would open the app and log water. It accepts a handful of URLs:
fluidics://fluidics.app/quickAdd
fluidics://fluidics.app/customAdd
fluidics://fluidics.app/add/:unit/:amount, where :unit is one of “flOz“, “l“, or “ml“, and :amount is a parsable number.
(Creating that linking framework was the spot where I was most tempted to drop SceneDelegate entirely – the Scene class’ onOpenURL(perform:) modifier was looking real nice compared to the tangle I wound up with in the SceneDelegate. Oh well, maybe for next update.)
One of the fun things to set up was the customizability of the widgets. I’ve bounced off the IntentKit framework in the past, but never got very far due to time constraints. With widgets being driven off Intents as well, though, it was time to sit down and actually write it up.
Honestly, the Intent definition editor is cool. I could go off on a whole mini-essay about the usefulness of constraints in design, and how perfectly it expresses the constraints of valid inputs and configurations, but I digress.
Having done that bit of setup, I’m definitely going to look more at this in the future. I’m still trying to figure out what, exactly, a SiriKit integration for Fluidics should look like; once I’ve done that design work, though, the coding aspect is seeming much more manageable now.
The last little feature I added was the ability for Pro users to switch the icon. It felt like the right kind of thing to lock behind the Pro subscription – a purely cosmetic tweak, and an additive change. Actually implementing it in SwiftUI was fun – it’s a Picker, attached to a custom Binding. I should probably refactor it a bit for readability, but the actual implementation is pretty solid, and I’m happy about it. It also allows for further expansion in the future – I can add new icon choices pretty easily, going forward, and may do so if I have any fun ideas for what to offer there. And yes, I’m open to suggestions.